快速入門強化學習(Reinforcement Learning)
前言
我會想寫這篇文章的原因,是希望使從未接觸過強化學習的讀者,能夠快速且有效率地入門強化學習。
讀者不需要擔心數學能力的問題,在文中只要能用中文解釋,就不會放公式上來,即便我放了公式,旁邊也一定會告訴讀者它代表的意思,基本上讀者只需要還記得高中的數學即可,必要的數學知識會在文中補充。
我原先計畫從 Markov chain 開始層層遞進,一直寫到現代熱門的 policy-based 方法為止,但是從 Reinforcement Learning 寫到 Model-based Methods 共五個章節就花了我至少 200 小時,這樣的時間花費對我來說過於昂貴,因此就先在 Model-based Methods 打住,至於剩下的章節就看看這篇文章的反響如何,如果反響熱烈的話我再找時間補上。
除了花費的時間太多以外,另一個不繼續寫下去的原因是剩下的內容在網路上都有著相當不錯的資料可供學習,相信讀者讀完前面的幾個章節,把 MDP 弄懂之後,能夠比較容易理解這些知識。
最後,由於我對強化學習的理解也僅是略識之無的程度,倘若文中出現任何錯誤,希望讀者能不吝指出,我會將有貢獻的讀者以及相關貢獻放在鳴謝部分。
注意
- 重要的專有名詞除第一次出現外,皆以英文呈現
- Medium 不支援 LaTeX,故部分數學符號使用 Unicode 表示
- 我刻意把公式分散在文章之中,請讀者自行整理文中出現的公式以便參考
- 全文禁止轉載
文章架構
打上 * 表示如果讀者已經有相關知識的話可以跳過。
打上 ** 表示較為深入的數學探討,如果只是想知道脈絡或數學跟我一樣差的讀者可以快速翻過(不是跳過)。
1 Reinforcement Learning
1.1 Introduction
1.2 Formulation of RL
2 Markov Chain
2.1 Markov chain
2.2 Sampling and Monte Carlo method*
2.3 Exercises
3 Markov Reward Process
3.1 Markov reward process
3.2 Random variable*
3.3 Expectation and variance*
3.4 Value function
3.5 Convergence of value function**
3.6 Exercises
4 Markov Decision Process
4.1 Markov decision process
4.2 Existence of optimal policies**
4.3 Action-value function
4.4 Optimal policy construction
4.5 Exercises
5 Model-based Methods
5.1 Policy and policy function
5.2 Value iteration
5.3 Policy iteration
5.4 Monte Carlo method
5.5 Exercises
— 以下內容未完成 —
6 Value-based Methods
6.1 Monte Carlo method
6.2 SARSA
6.3 Q-learning
6.4 Neural network approximation
7 Policy-based Methods
7.1 Policy gradient
7.2 REINFORCE
7.3 Actor-critic
8 Search Algorithms
8.1 Monte Carlo tree search
1 Reinforcement Learning

1.1 Introduction
強化學習(reinforcement learning,簡稱 RL)由兩個概念組成,分別是做出動作的代理人(agent)和與代理人互動的環境(environment)。代理人會根據狀態(state)來決定所要採取的動作(action),而環境會根據狀態和代理人的動作,反饋一個獎勵(reward),並轉換到下一個狀態,如此循環往復,也就是說代理人和環境的互動看起來像是:
- 初始狀態 s₀
- agent 根據 s₀ 做出 a₀
- environment 根據 s₀、a₀ 反饋 r₀
- environment 根據 s₀、a₀ 轉換到 s₁
- agent 根據 s₀、a₀、s₁ 做出 a₁
- environment 根據 s₀、a₀、s₁、a₁ 反饋 r₁
- environment 根據 s₀、a₀、s₁、a₁ 轉換到 s₂
- agent 根據 s₀、a₀、s₁、a₁、s₂ 做出 a₂
- environment 根據 s₀、a₀、s₁、a₁、s₂、a₂ 反饋 r₂
- environment 根據 s₀、a₀、s₁、a₁、s₂、a₂ 轉換到 s₃
- ……
等等,為什麼上面的過程看起來這麼複雜?原因其實很簡單,因為這個世界本就這麼複雜,以下用校園生活來舉例:
- 學生必須在某些課堂中(state)學到某些知識(action),才能在考試(state)中寫出答案(action)
- 學生必須連續數次考試(state)得到高分(action),老師才會開心(reward)
- 學生必須所有考試(state)都及格(action)才不會被留級(state)
而這三種情況可以類比為:
- agent 根據 s₀、a₀、s₁、a₁、s₂ 做出 a₂
- environment 根據 s₀、a₀、s₁、a₁、s₂、a₂ 反饋 r₂
- environment 根據 s₀、a₀、s₁、a₁、s₂、a₂ 轉換到 s₃
除了上面的例子外,其實許多 RPG 遊戲也是如此,讀者可以試著思考看看。既然我們一不小心就把校園生活變成一個 RL 的過程,那麼不妨思考一下這個 RL 的最終目標是什麼呢?那就是讓學生(agent)在學校就讀(environment)的過程中,讓老師的開心(reward)次數越多越好。(這只是舉例,我並不贊同這件事)
至此,我們能夠推理出為什麼除了 state 和 action 外,還需要有 reward 的理由了,這是因為 agent 需要有 reward 才得以判斷先前採取的 action 的優劣,並進行學習,使得下一次的 action 能夠得到更多的 reward,總體而言,這樣的流程即是所謂的 RL,所以說:
- RL 實際上是一種訓練的框架
- agent 是需要學習的模型(決策樹、神經網路等等)
- environment 是我們想要最佳化的問題
- agent 要想辦法從 environment 中拿到盡量多的 reward
現在我們已經有了 agent 和 environment 的概念,但還是不太清楚要怎麼用數學來表達 agent、environment 和彼此之間的互動過程,不過不用擔心,接下來就讓我一步步揭開它們背後的神秘面紗。
題外話一下,其實強化學習也可以套用到我們的日常生活中,舉例來說,如果我們想要做到長期才能見到效果的事情,那麼可以適時替自己設定一些reward,讓大腦知道做這些事情是有益處的,從而堅持下去,最終達成目標。
1.2 Formulation of RL
前面說到 environment 是我們要最佳化的問題,但也舉了例子來指出現實世界的問題的複雜性,在這種情況下,要用數學去描述這些問題是非常不容易的,因此我們需要透過一些假設來簡化它們,得到一個我們能夠處理的新問題,再用新問題中的最佳 agent 來近似原問題的最佳 agent。
那麼要怎麼簡化呢?一個可行的思路是:
- 初始狀態 s₀
- agent 根據 s₀ 做出 a₀
- environment 根據 s₀、a₀ 反饋 r₀
- environment 根據 s₀、a₀ 轉換到 s₁
- agent 根據 s₁ 做出 a₁
- environment 根據 s₁、a₁ 反饋 r₁
- environment 根據 s₁、a₁ 轉換到 s₂
- agent 根據 s₂ 做出 a₂
- environment 根據 s₂、a₂ 反饋 r₂
- environment 根據 s₂、a₂ 轉換到 s₃
- ……
也就是說 action 只由當前 state 決定,reward 和下一個 state 只由當前 state 和 action 決定,這個思路即是馬可夫決策過程(Markov decision process,簡稱 MDP),是 RL 的重要理論基礎。
敏銳的讀者這時可能會有個疑問,那就是如果想解決的問題沒辦法形式化為一個 MDP 要怎麼辦,這樣還能套用 RL 嗎?我必須說這是個非常好的問題,針對這個問題,我在此提出兩個辦法,第一個是從頭建立一套適用於該問題的強化學習理論,從源頭解決問題,而第二個是多訓練幾個 agent,然後祈禱有個 agent 能跑出不錯的結果。
說回 MDP,MDP 實際上是由馬可夫鏈(Markov chain)、reward 和 action 所得來,我們先簡單介紹一下 Markov chain 和一些相關的機率學知識,以便後續的理解。
2 Markov Chain
2.1 Markov chain
Markov chain 又稱 Markov process,包含:
- 由所有 state 組成的集合 S(state space)
- 轉移機率 ℙ[v|s](transition probability):給定 state v 和 state s,得到由 state s 轉移到 state v 的機率
在 Markov chain 中有個很重要的前提,那就是「當前 state 轉移到下一個 state 的機率不受先前 state 的影響」,這個性質又稱馬可夫性質(Markov property),請讀者銘記於心。

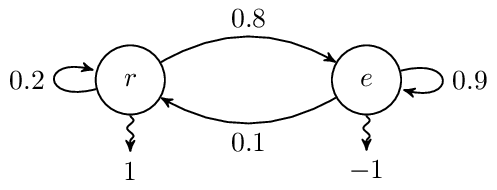
上圖為一個簡單的 Markov chain,其中以 r 表示讀書,以 e 表示吃飯,實線表示 transition probability,從圖中我們可以知道:
- S = {r, e}
- ℙ[r|r] = 0.2(在讀書的情況下,有 20% 的機率繼續讀書)
- ℙ[e|r] = 0.8(在讀書的情況下,有 80% 的機率跑去吃飯)
- ℙ[r|e] = 0.1(在吃飯的情況下,有 10% 的機率跑去讀書)
- ℙ[e|e] = 0.9(在吃飯的情況下,有 90% 的機率繼續吃飯)
我們以 {s₀, s₁, s₂, …} 來表示一個序列(sequence,也有人稱其為 trajectory),透過以上的資訊,我們可以輕易求得某一個 sequence 發生的機率,例如 {r, e, r} (讀書 → 吃飯 → 讀書)的機率為 1 × 0.8 × 0.1 = 8%、{e, e, e}(吃飯 → 吃飯 → 吃飯)的機率為 1 × 0.9 × 0.9 = 81%。
接下來我們仔細看的話可以發現:
- ℙ[r|r] > 0、ℙ[e|r] > 0
- ℙ[r|r] + ℙ[e|r] = 1
在機率學中,我們稱 ℙ[∙|r] 是一個定義在 S 上的機率質量函數(probability mass function,簡稱 PMF),當我們把 ∙ 用 S 中的元素,也就是 r 或 e 帶入後,就能得到在給定 r 的情況下,轉移到 r 或 e 的 transition probability;同理可知 ℙ[∙|e] 也是個定義在 S 上的 PMF。總而言之,看到 PMF,除了知道它能給出機率以外,還要記得它本身是定義在什麼之上的。
為什麼這裡要提到 PMF 呢?因為我們可以把 Markov chain 看成是由很多個 state 以及很多個關於這些 state 的 PMF 所組成的,以上面的情況來說,就是 r、 e、ℙ[∙|r] 和 ℙ[∙|e]。
2.2 Sampling and Monte Carlo method*
用上面的例子我們來談談採樣(sample),進行一次採樣簡單來說就是從一個 PMF 中選出一個 state,例如在 ℙ[∙|r] 中只有 r 和 e 兩個 state 存在大於 0 的機率,因此只要多做幾次,我們就可以從 ℙ[∙|r] 採樣出 r 和 e 兩個 state。sample_PMF()是我隨便寫寫的採樣函數,有興趣的讀者可以拿來測試看看剛剛說的是否正確,另外也能試試看是否採樣的次數足夠多之後,所有 state 出現的機率會趨近 PMF。
我在將隨機種子(random seed)設置為 0 的情況下,對 ℙ[∙|r] 採樣了一百萬次,計算一下得到 r 和 e 的機率分別為 19.9928% 和 80.0072%,用數學表示就是 ℙ[r|r] ≈ 19.9928% 以及 ℙ[e|r] ≈ 80.0072%,與前面設定的 20% 和 80 % 非常接近。
現在有了sample_PMF(),接著可以估算某個 sequence 出現的機率了。以下還是我隨便寫寫的程式碼,如果有想嘗試跑跑看的讀者,請參考 seq_prob()函數的說明。
同樣地,我將 random seed 設為 0 後,透過採樣一百萬筆長度為 3 的 sequence,得到 {r, e, r} 出現的機率為 8.0245%,接近前面計算出來的 8%;{e, e, e} 出現的機率為 81.0017%,接近前面計算出來的 81%。
實際上,根據大數法則(law of large numbers),只要我們採樣的次數越多,統計出來的機率會越接近 PMF,反過來說,即便我們並不知道 PMF 本身,但因為大數法則的存在,我們能夠利用大量採樣去逼近原本的 PMF,像這樣的方法被稱為是蒙地卡羅方法(Monte Carlo method),這個思想在 RL 中會常常見到。
2.3 Exercises
給定 S = {r, e}、ℙ[r|r] = 0.2、ℙ[e|r] = 0.8、ℙ[r|e] = 0.1 和 ℙ[e|e] = 0.9 構成 Markov chain。
- 求 {r, e, r} 出現的機率。
- 令所有長度為 3 的 sequence 為一集合,求該集合對應的 PMF。
3 Markov Reward Process
3.1 Markov reward process
馬可夫獎勵過程(Markov reward process,簡稱 MRP)是在原有的 Markov chain 上加入 reward 而來,包含:
- 由所有 state 組成的集合 S(state space)
- 轉移機率 ℙ[v|s](transition probability):給定 state v 和 state s,得到由 state s 轉移到 state v 的機率
- 獎勵函數 R(s)(reward function):給定 state s,得到相應的 reward
- 折扣因子 γ(discount factor),一個介於 0 到 1 的實數
什麼是 reward 呢?Reward 是進入一個 state 後得到的分數。我們假設 R(r) = 1(讀書的 reward 是 1)、R(e) = −1(吃飯的 reward 是 −1),把它們加回 Markov chain 的圖中可以得到一個 MRP:
其中彎曲的線表示進入該狀態所得到的 reward。
定義好 reward function,我們可以計算任意 sequence 的 reward 之和,例如 {r, e, r} 的 reward 之和為 R(r) + R(e) + R(r) = 1,那麼怎樣的 sequence 會讓 reward 之和最高呢?其實只要一直讀書就行了對吧。
現在要來說說 discount factor 的用處了,先看下面這個式子:
請注意 sᵢ 指的是一個 sequence 中的第 i 個 state,而不是特定的某個 state。
依照上式,當 γ 為 1 時,reward 之和為 R(s₀) + R(s₁) + R(s₂) + …,跟沒加入 γ 的情況一樣;當 γ 為 0 時,reward 之和為 R(s₀);當 γ 為 0.5 時,reward 之和為 R(s₀) + 0.5×R(s₁) + 0.25×R(s₂) + …。
相信讀者可以猜到為何 γ 被叫做 discount factor 了,因為當 γ < 1 時,越後面的 reward 被打上的折扣越多,但這有什麼用呢?
- 如果一直都在讀書的話,γ < 1 可以使得 reward 之和不會變得無窮大。
- 有些時候我們更關注前面幾個 state 得到的 reward,例如我們會覺得先讀完書再去吃飯比一下子讀書一下子吃飯還要好,也就是說前者的 reward 之和會比後者的高,而 γ < 1 能夠幫助我們做到這件事。
- 後續的數學推導需要 γ < 1 的假設
接下來由於上面的式子只能得到整個 sequence 的 reward 之和,沒辦法表示第 i 個 state 之後的 reward 之和,為了讓生活輕鬆點,我們可以再定義一個式子來表示它:
在之後的文章裡我會簡單地把 G 稱為 return,因為 reward 之和看起來怪彆扭的。另外當 G 有一個下標,例如 i 時,則 Gᵢ 的意思是從第 i 個 state 開始算起的 return。
現在來分析一下 G,考慮 {r, e, r},我們知道 G₀、G₁ 和 G₂ 的值分別為 R(r) + γR(e) + γ²R(r)、R(e) + γR(r) 和 R(r),通過仔細觀察,可以發現 G₀、G₁ 和 G₂ 之間存在遞迴關係:
- G₂ = R(r)
- G₁ = R(e) + γR(r) = R(e) + γG₂
- G₀ = R(r) + γR(e) + γ²R(r) = R(r) + γ(R(e) + γR(r)) = R(r) + γG₁
將這個關係一般化,可以得到:
這個結論會在待會提到 value function 時扮演很重要的角色。
3.2 Random variable*
在機率學中,期望值(expectation)和變異數(variance)是觀察 PMF 特性的重要指標。
在這之前,我們先來什麼是討論什麼是隨機變數(random variable),在機率學中,一個 random variable 由兩個部分組成,分別是樣本空間(sample space)和將 sample space 的元素映射到某一實數的函數,sample space 簡單講,就是我們進行採樣時有可能得到的東西,以 Markov chain 的例子來說, sample space 就是 {r, e},至於需要映射的原因是如果我們的 sample space 的元素不是數字,那麼我們無從對其進行計算,所以會需要一個函數來將元素轉變為數字,舉個實際的例子,考慮 {r, e},我們可以把 r 映射成 0,e 映射成 1,也就是 f(r) = 0 和 f(e) = 1。
令 X = (S, f),若給定具體的 S 和 f 時,我們可以直接把它展開為一個個的元素所構成的集合,比如說給定 S = {r, e} 和 f = {r → 0, e → 1} 後,可以直接把 X 寫成 {0, 1},利用這個結果,回到在 Markov chain 部分提到的「ℙ[∙|r] 是一個定義在 S 上的機率質量函數」應該要改成「ℙ[∙|0] 是一個定義在 X 上的機率質量函數」才會是稍微精準一點的說法。
總結一下,如果沒辦法拿 S 來運算,那麼透過一個函數把 S 的元素改成可以計算的數字就好,這就是上面想表達的意思。
3.3 Expectation and Variance*
當給定 random variable X 以及基於 X 的 PMF p,則 X 的 expectation 由下式給出:
它實際上就是用機率加權的平均數,有了這個式子,我們可以計算由 r 轉移到下一個 state 的 expectation,沿用上面提到的 X,我們先改寫一下原本的 ℙ[∙|r] 使其成為基於 X 的 ℙ[∙|0],也就是把 ℙ[r|r] = 0.2 和 ℙ[e|r] = 0.8 分別改成 ℙ[0|0] = 0.2 和 ℙ[1|0] = 0.8,有了這些數字,帶入上式得到 𝔼[X] = 0.2 × 0 + 0.8 × 1 = 0.8,雖然好像沒有這個必要,但我們可以詮釋 0.8 為 r 傾向於轉移到 e。
接下來要提的是 variance,其公式如下:
從公式中可以看出來,只要 X 中的元素離 𝔼[X] 越遠,則 Var(X) 的值會越大,反之則越小,由於後續只會小小的提到 variance,所以我們只需要知道它代表一個 random variable 的分散程度。
3.4 Value function
我們將 value function 記作 V(s),代表從 state s 開始算起的 expected return,這基本上就是把前面的 return 公式套上一個 expectation 而已。
上式的 sᵢ = s 只是想表示 sequence 的第 i 個 state 是 s 而已,如果還是不懂的話,就把 V(s) 當作是以 state s 開頭的所有 sequence 的 expected return。總之在這邊只要知道 value function 是在 MRP 中引入的,並且知道它代表的意思就好。
3.5 Convergence of value function**
接下來我們好奇的是要怎麼確定 V(s) 在 γ < 1 的情況下會收斂到某個數,如果不收斂的話,那就沒什麼好討論的對吧?想要證明確實會收斂,實際上要分兩步來思考,首先我們要知道何謂 stationary distribution。
給定一個初始 distribution(假設是個 row vector,例如 [1 0] 表示 r 的機率是 1,e 的機率是 0),如果右乘一個 right transition probability matrix 足夠多次後,能夠得到一個 row vector,使得它自身右乘 right transition probability matrix 後仍會得到自己,則我們稱該 row vector 是一個 stationary distribution,在這個例子裡 stationary distribution 會是 [1/9 8/9],意思是經過很多次 transition 後,有 1/9 的機率會在 r,有 8/9 的機率會在 e。
接下來證明 V(s) 在 γ < 1 的情況下會收斂到某個數。首先若給定的 MRP 存在 stationary distribution,易知 1. 到達 stationary distribution 後的 expected reward 為一常數,又知 2. 公比介於 (−1, 1) 之間的無窮等比級數和為一常數,令 x 為 MRP 到達 stationary distribution 的時間點,因為 x 是個整數,所以在 x 之前的 expected reward 之和為一常數;雖 x 之後的 expected reward 有無窮多項,但由 1. 和 2. 保證其為一常數,綜合可知 V(s) 在 γ < 1 且存在 stationary distribution 的情況下會收斂到某個數,得證。
因為這個 MRP 存在 stationary distribution 且 γ 為 0.5,所以我們知道 V(r) 和 V(e) 都會是某個具體的數字,以上是我計算 V(r) 的過程,讀者可以把 i = 0 代入展開看看這個式子代表什麼。
附帶一提 V(s) 也能透過求解線性方程組來得到,首先回想起 return 可以寫成遞迴形式,因為 V(s) 是從 return 加個 expectation 來的,所以 V(s) 也能寫成遞迴形式如下:
其中 v ∈ S 為 s 轉換到的下一個 state,因為 R(s) 和 γ 是固定的,所以可以把它們拿到 expectation 外面。
接著分別將 V(r) 和 V(e) 帶入上式得:
接下來要做的就只有帶入數字、化簡和解方程組而已,有興趣的話還可以把上面的式子一般化成矩陣形式。
3.6 Exercises
給定 S = {r, e}、ℙ[r|r] = 0.2、ℙ[e|r] = 0.8、ℙ[r|e] = 0.1、ℙ[e|e] = 0.9、R(r) = 1 和 R(e) = −1 構成 MRP。
- 令 γ 為 1,求長度為 3 的 sequence 的 expected return。
- 令 γ 為 0.5,求 V(e)。
4 Markov Decision Process
4.1 Markov decision process
我們現在終於正式進入 MDP 了,跟從 Markov chain 變成 MRP 的概念相似,MDP 實際上就是以 MRP 為基礎加入 action 得到的,一個 MDP 包含:
- 由所有 state 組成的集合 S(state space)
- 由所有 action 組成的集合 A(action space)
- 轉移機率 ℙ[v|s, a](transition probability):給定 state v、state s 和 action a,得到根據 action a 由 state s 轉移到 state v 的機率
- 策略 𝜋[a|s](policy):給定 state s 和 action a,得到選擇 a 的機率
- 獎勵函數 R(s, a)(reward function):給定 state s 和 action a,得到相應的 reward
- 折扣因子 γ(discount factor),一個介於 0 到 1 的實數
上圖是原本的 MRP,我們在其基礎上增加兩個動作,分別是餓(以 h 表示)和不餓(以 n 表示),可以得到:
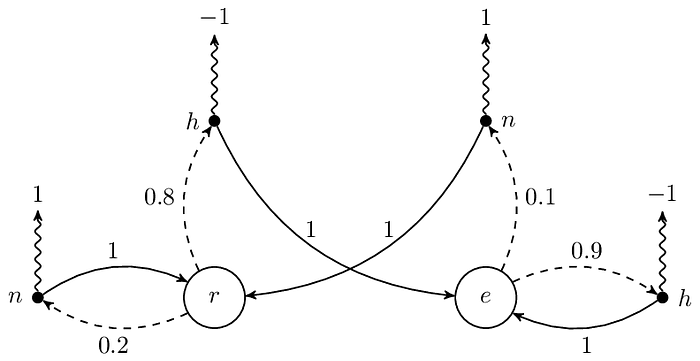
在上圖中,黑點是 action,虛線是 state 到 action,而實線是 action 到下一個 state,曲線是 reward,例如在 r 時有 80% 的機率選擇 h,選擇 h 的話得到 −1 的 reward 並 100% 轉移到 e。請記得這個轉移是一口氣完成的,換言之,上一個時間點會在一個 state 上,而下一個時間點也會在一個 state 上,而非在一個 action 上,因為 action 並不是 state。這兩張圖基本上是等價的,讀者可以對比看看兩張圖的差別,等到理解了再往下看。
另外,不要問我為什麼吃飯和讀書是狀態,而餓和不餓是動作。對,沒錯,我也覺得吃飯和讀書應該要是動作,餓和不餓才是狀態,可是我前面圖都做了,字都打了,總不能叫我砍掉重練吧?而且換個角度來看,其實產生飢餓感或飽足感都可以說成是一種「動作」,那麼在某種意義上餓和不餓也能看成是一種動作吧,這個說法我覺得算是挺合理的,至於你信不信,我反正信了。
在講 policy 之前,我們先來討論 transition probability,先前在 Markov chain 時曾經提過 ℙ[∙|s] 是個 PMF,相似地,在 MDP 中,ℙ[∙|s, a] 也是個 PMF,只不過要多給一個 action a 而已。以下列出相應的 transition probability:
- ℙ[r|r, h] = 0.0(在讀書的情況下肚子餓,有 0% 的機率繼續讀書)
- ℙ[e|r, h] = 0.8(在讀書的情況下肚子餓,有 80% 的機率跑去吃飯)
- ℙ[r|r, n] = 0.2(在讀書的情況下肚子不餓,有 20% 的機率繼續讀書)
- ℙ[e|r, n] = 0.0(在讀書的情況下肚子不餓,有 0% 的機率跑去吃飯)
- ℙ[r|e, h] = 0.0(在吃飯的情況下肚子餓,有 0% 的機率跑去讀書)
- ℙ[e|e, h] = 0.9(在吃飯的情況下肚子餓,有 90% 的機率繼續吃飯)
- ℙ[r|e, n] = 0.1(在吃飯的情況下肚子不餓,有 10% 的機率跑去讀書)
- ℙ[e|e, n] = 0.0(在吃飯的情況下肚子不餓,有 0% 的機率繼續吃飯)
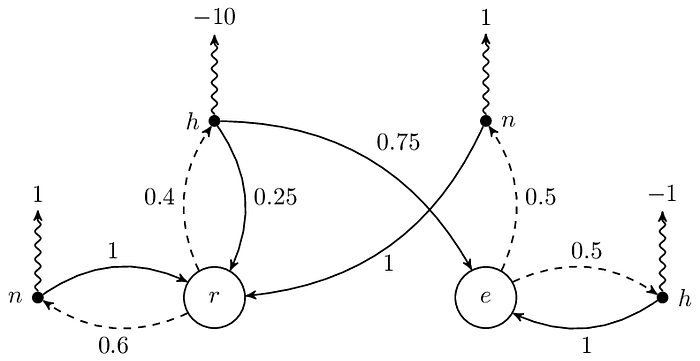
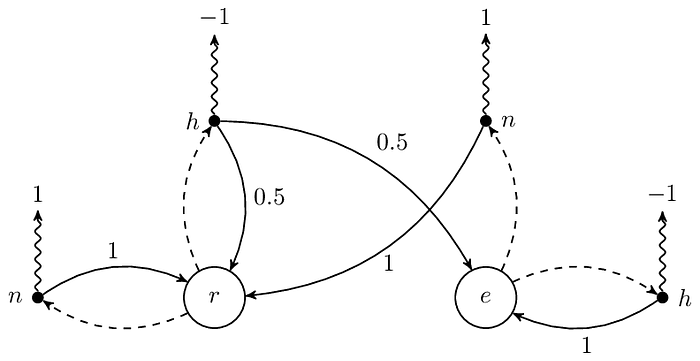
請注意機率為 0 的部分,雖然上面的例子裡它們為 0,但這不代表在其他的 MDP 中它們會是 0。讓我們看看把 ℙ[r|r, h] 和 ℙ[e|r, h] 分別改成 0.2(也就是 0.8 × 0.25)和 0.6(也就是 0.8 × 0.75)之後,相對應的圖會長怎樣:
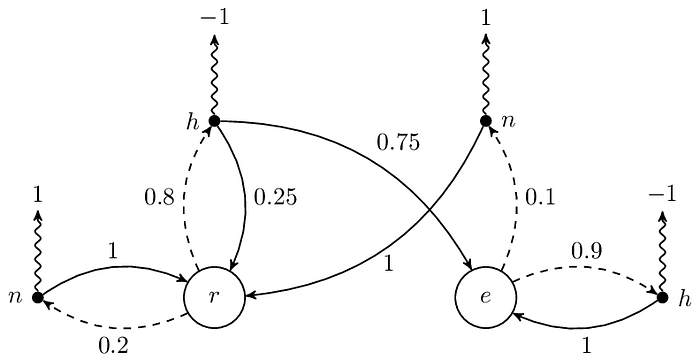
總之這裡想表達的意思是即便每次都採取一樣的 action,但轉移到的 state 有可能不同,這跟在 Markov chain 或 MRP 中的 state 轉移是一樣的。總結一下,這裡的 transition probability 由四個 PMF 決定 ℙ[∙|r, h]、ℙ[∙|r, n]、ℙ[∙|e, h] 和 ℙ[∙|e, n]。
接下來要說的就是 policy 了,在 MRP 中,因為 transition probability 是固定的,所以我們實際上沒什麼事好做,頂多就是算算 return 或 expected return 而已,不過在 MDP 就不一樣了,假設從 r 開始,即便 transition probability 是固定的,但我們能夠調整 action 的選擇機率,使得我們走的 sequence 的 return 能夠最大化,例如我們只要把上圖虛線的 0.2 和 0.8 分別改成 1 和 0,就能在 r 時一直選擇 n 而一直回到 r,瘋狂賺取 reward。
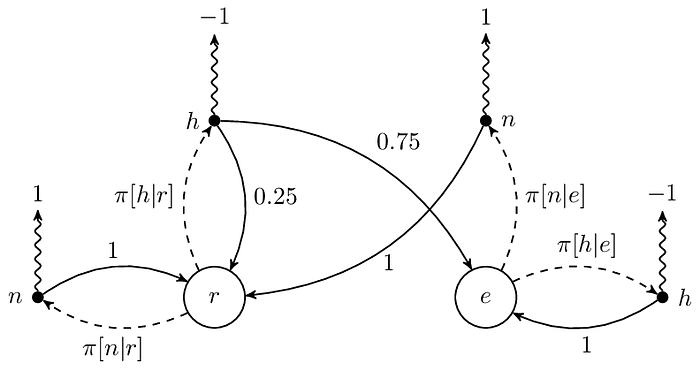
看到這裡相信讀者知道我想表達什麼了,沒錯,令 𝜋 表示 policy,則 𝜋 是由好幾個 PMF 所組成的,例如在上圖中 𝜋 可以分解成 𝜋[∙|r] 和 𝜋[∙|e]。另外提醒一下,因為 state 不同,所以同一個 action 的 reward 可以是不一樣的,例如 R(r, h) 和 R(e, h) 的值都是 −1,但我們可能希望在讀書的時候比較不會選擇肚子餓,而把 R(r, h) 改成比 −1 還小的數字,如下圖的 −10,以示懲罰。
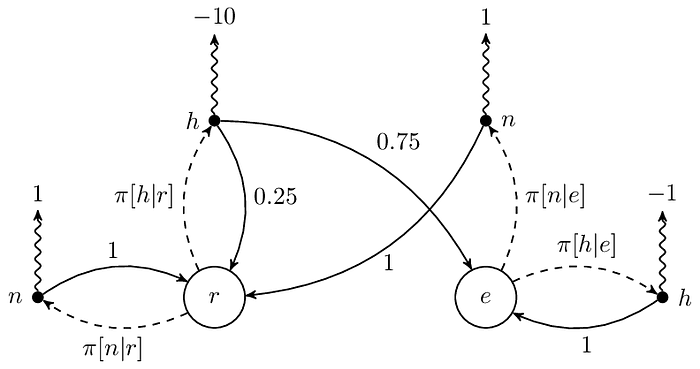
總體來說,在 MDP 裡共有兩個 PMF 的集合,分別是 transition probability 和 policy,前者與 reward function 一起構成 environment 的數學模型,而後者單獨構成 agent 的數學模型。
4.2 Existence of optimal policies**
假定優化目標是 return 越高越好,那麼現在問題落到了怎麼找到最佳的(optimal) policy,對於這個問題,後續的全部章節都在討論這件事。
在此之前,我們需要思考的是 optimal policy 到底存不存在,如果不存在的話再怎麼討論都是白搭,當然,由於後續的章節都在討論找 optimal policy 的方法,所以一定是存在的,不過還是需要思考一下對吧?
我們先把在 MRP 提到的遞迴版 value function 拓展成 MDP 版本的:
好吧,嚴謹一點應該寫成這樣:
這個式子怎麼看起來這麼複雜?我也沒辦法,會長這樣的最主要原因是 a 不是固定的,因此需要用 expectation 包起來,接著算 R(s, a) 的 expectation 用到的 PMF 是 𝜋[∙|s],而算 V(v) 的 expectation 用到的 PMF 是 ℙ[⋅|s, a],並且 ℙ[⋅|s, a] 的 a 跟 𝜋[∙|s] 相關,所以這個式子寫下來之後,不像 MRP 的那樣有可以簡化的地方。
在 MRP 中只會有一個 V(s),解法在之前已經提及,但在 MDP 中 V(s) 跟 policy 有關,這是為什麼 V 的旁邊會有個小 𝜋 的緣故,當知道具體的 policy 為何,我們可以像在 MRP 提到的那樣,根據 V(s) 的遞迴公式來列出線性方程組,進而求解。
接下來再介紹另一個求 V(s) 的思路。還記得剛開始把 MRP 轉變成 MDP 的過程嗎?這表示我們可以把 MRP 擴展成一個等價且帶有固定 policy 的 MDP,反過來說,有著固定 policy 的 MDP 可以被轉換成一個等價的 MRP,別忘了我們知道如何解出 MRP 的 V(s),這表示有著固定 policy 的 MDP 可以藉由被轉換成等價的 MRP 進而求得 V(s),這段話讀起來有點繞,讀者可以翻回前面看看那兩張圖,好好品味這番話。
當然,前面那個例子是由 MRP 轉到有固定 policy 的 MDP,所以容易轉回去 MRP,那麼如果是我們後面魔改的版本呢?那也簡單,我們可以輕易把 MDP 的 𝜋 跟 ℙ 融合在一起,得到 MRP 的 ℙ,思路可以參考有 0.25 和 0.75 那張圖的前後文。現在 ℙ 有了,那要弄出 MRP 對應的 reward function 也容易,我們用 𝔼[R(s, a)] 來當作 MRP 的 R(s) 即可。
好了,現在我們知道有著固定 policy 的 MDP 可以求得 V(s),對於一個 MDP,會有很多個可能的 policy,這些 policy 根據上面的推論,都可以找到一個相應的 V(s),這些 V(s) 可能重複也可能不重複,總之存在一個以上的 V(s) 就是了。
現在定義一個函數 T,該函數會在原有 V(s) 的基礎上構造出一個相應的 V’(s),T 的定義如下:
它其實就是把遞迴版 V(s) 的 expectation 拔掉換成 max 而已。
觀察上式可知 V(s) 經過 T 映射後得到的 V’(s) 一定不會比較差,為什麼呢?因為原有的 V(s) 是 expectation,也就是加權平均數,但 V’(s) 是取原本要拿去加權平均的這些數之中的最大值,因此給定一樣的 state,V’(s) 的值一定不小於 V(s),也就是 V’(s) 一定不會比 V(s) 差,換言之,T 可以幫助我們得到更好的 value function。
T 實際上被稱作 Bellman operator,有興趣的讀者可以去查查看 Bellman 和他提出的 Bellman equation,你會發現原來演算法提到的動態規劃(dynamic programming)背後的理論就是出於 Bellman 之手,另外求最短路徑的 Bellman-Ford 演算法的 Bellman 也是他本人。
以上標 * 表 optimal,考慮 V*(s),經過 T 映射後,我們可以預期 V*(s) = T(V*(s)),否則 V*(s) 就不會是最佳的。因為 V*(s) = T(V*(s)) 成立,所以 V*(s) = T(V*(s)) = T(T(V*(s))) = … 恆成立,我們稱 V*(s) 是 T 的一個不動點,因為不論經過多少次迭代 V*(s) 都不會變。前面提到 T 能讓我們得到更好的 V(s),這一段提到當 V(s) = T(V(s)) 成立時 V(s) 即為 V*(s),但是從這些論述中並不能知道 V*(s) 是不是唯一的。
接下來的目標是透過巴拿赫不動點定理(Banach fixed-point theorem)來證明對 V(s) 執行很多次的 T,能夠得到一個獨特的不動點 V*(s),也就是說只存在唯一一個 V*(s)。
Banach Fixed-point Theorem
Let (M, d) be a complete metric space.
Let f : M → M be a contraction mapping.
Then there exists a unique fixed point of f.
假設 state space 內共有 n 個 state,又 V(s) 的對應域是實數 ℝ,我們可以建立一個空間 ℝⁿ,也就是 n 維的實數空間(讀者可以想像一個三維空間,然後一直告訴自己這是 n 維空間,應該會比較好接受一點),這麼一來我們能把一個 V(s) 轉化變成該空間內的一點(把 n 個 state 丟進 V(s) 會得到 n 個實數,這 n 個實數就是坐標),顯然 T(V) 和 V 都是 ℝⁿ 上的點集合,換個說法就是 T : ℝⁿ → ℝⁿ(同空間的映射)。
現在引入 infinity norm,給定兩坐標點,將兩點相減得一向量,則 infinity norm 即為該向量的所有分量取絕對值後的最大值,式子如下:
其中 V₁ 和 V₂ 為 ℝⁿ 中兩點(其實就是兩個 value function)。接著我們用 infinity norm 來定義 ℝⁿ 上的兩點距離,此時 (ℝⁿ, d) 滿足 complete metric space 的定義。
我們先來證明以下不等式是正確的,這個不等式在後面會用到。
設 x、y 和 z 分別使 f₁、f₂ 和 |f₁ − f₂|有最大值,考慮:
- f₂(x) ≤ f₂(y) ⇒ |f₁(x) − f₂(y)| ≤ |f₁(x) − f₂(x)|
- f₁(y) ≤ f₁(x) ⇒ |f₁(x) − f₂(y)| ≤ |f₁(y) − f₂(y)|
- |f₁(x) − f₂(x)| ≤ |f₁(z) − f₂(z)|
- |f₁(y) − f₂(y)| ≤ |f₁(z) − f₂(z)|
綜合得到 |f₁(x) − f₂(y)| ≤ |f₁(z) − f₂(z)|,得證。
最後只需要證明 T 是 contraction mapping 就能套用 Banach fixed-point theorem 了。我們令 V₁ ∈ ℝⁿ 和 V₂ ∈ ℝⁿ,如果 T 是 contraction mapping,必須滿足以下關係:
其中 α 為 [0, 1) 中的某些數字。這個式子告訴我們轉換後的兩點距離會比轉換前的還小,也就是轉換後相比轉換前經過了「壓縮」。
接下來展開上式的右邊部分,以下 f(a) 表示 R(s, a) + γ𝔼ᵥ[V(v)]:
以 γ 替換 α,得到 d(T(V₁), T(V₂)) ≤ αd(V₁, V₂),故 T 是 contraction mapping,得證。
綜合上面的討論,由於 (ℝⁿ, d) 是 complete metric space 且 T : ℝⁿ → ℝⁿ 是個 contraction mapping,故根據 Banach fixed-point theorem 得到 V*(s) 存在且唯一,意即存在 optimal policy。
需要注意的是 optimal policy 可能不只一個,這是為什麼標題是 existence of optimal policies 的原因,另外當 γ = 1 時 T 不會是 contraction mapping,所以不適用此結論。
4.3 Action-value function
在 Markov chain 和 MRP 中,我們把 sequence 表示成 {s₀, s₁, s₂, …},不過在 MDP 中,因為 action 也參與了 state 的轉換,我們需要把 sequence 表示成 {s₀, a₀, s₁, a₁, s₂, a₂, …}。或許在有些地方會看到 reward 也被記錄在 sequence 裡,不過因為在 MDP 中要求 reward 是個函數,也就是說不存在 R(s, a) 會有不同值的情況,所以我們可以透過 R(s, a) 取得相應的 reward 即可,而不用另做紀錄。
我們把 action-value function 記作 Q(s, a),表示 state s 和 action a 的 expected return。
它的形式跟 V(s) 相比就只是多了 a 而已,實際上 V(s) 和 Q(s, a) 存在以下關係:
可以看出來 Q(s, a) 比 V(s) 包含了更多訊息。
同樣地,我們也能像 V(s) 那樣把 Q(s, a) 寫成遞迴形式:
因為 Q(s, a) 有兩個參數,所以需要用兩個 expectation 包起來。
前面提到 V(s) 版本的 Bellman operator T,這邊也可以按照同樣的思路,拔掉 expectation 改成 max 來得到 Q(s, a) 版本的 Bellman operator U:
既然 U 都叫 Bellman operator 了,這表示透過 U 能夠找到唯一的 Q*(s, a)。
雖然讀者看起來可能會覺得有些突兀,不過 Q(s, a) 可以說是 Value-based Methods 章節中的核心。
4.4 Optimal policy construction
前面提到透過 T 或 U 能夠得到唯一的 V*(s) 或 Q*(s, a),但是 optimal policy 可能不只一個,那麼要怎麼從 V*(s) 或 Q*(s, a) 得到一個 optimal policy 呢?
首先回憶起 𝜋 是一群 PMF 的集合,而 𝜋[⋅|s] 是個 PMF,意思是給定 s 後代入 a 就能得到在 s 的情況下選擇 a 的機率,假設我們能知道在給定 s 的情況下的optimal action a*,那麼可以讓 𝜋[a*|s] 的值為 1,其餘 action 的值為 0,也就是說在給定 s 的情況下永遠選擇 a*,接下來只要對每個 PMF 都做同樣的事情,那麼綜合起來的這些 PMF 就是一個 optimal policy 𝜋*。
接下來的問題是要怎麼得到 a*。假設 Q*(s, a) 已知且給定 s,則有:
為什麼這樣能得到 a* 呢?因為 Q(s, a) 是給定 s 和 a 的 expected return,而 Q* 又是 optimal,所以把所有 action 代入 Q* 後,看哪個 action 的 expected return 最大,那麼那個 action 就是我們要的 a*。
同理可知若給定 s,則 V*(s) 與 a* 的關係如下:
這個式子的意思是在給定 s 的情況下,看看哪個 action 轉移到的下個 state 的 value function 值最大。
總結來說,只要知道 V*(s) 或 Q*(s, a),我們就能夠建構出一個 optimal policy。
4.5 Exercises
- 求 V(r) 和 V(e)。
- 畫出上圖對應的 MRP。
- 利用該 MRP 求 V(r) 和 V(e)。
令 S 的元素個數為 n、A 的元素個數為 m,建立實數空間:
顯然 U 是同空間的映射,接著在該空間上定義 infinity norm:
現在只需要證明 U 是 contraction mapping 後就能夠套用 Banach fixed-point theorem,確保經過很多次 U 的映射後,存在一個獨特的 Q*(s, a)。
- 驗證 d(U(V₁), U(V₂)) ≤ αd(V₁, V₂) 成立,其中 α ∈ [0, 1)。
5 Model-based Methods
從本章節開始,我們開始討論如何找出 𝜋*,基本來說,當知道 transition probability 時,只要設計好 reward function,我們就能夠用下面介紹的方法得出 𝜋*,這種需要知道 transition probability 的方法我們稱之為 model-based 方法。
回到 V(s) 的 Bellman operator T:
這個式子以演算法的角度來說,即是 V(s) 的 optimal substructure,是本章節方法的核心(因為它們本質上都是 dynamic programming),希望讀者先前就有發現到這件事。在進入如何找出 𝜋* 之前,我們先看看 policy 和 policy function 到底有什麼不同。
5.1 Policy and policy function
Policy 是很多個 PMF 的集合,這句話先前已經重複過很多次了,需要強調的是 policy 本身不滿足 function 的定義,因為 policy 輸出的 action 是基於 PMF 的機率決定的(換句話說就是採樣),並不保證每次得到的 action 都相同,所以說不能把 policy function 跟 policy 畫上等號,那麼什麼是 policy function 呢?
如果所有 PMF 都只有某個 action 的機率為 1 的話,不管對同一個 PMF 採樣多少次,都只會得到一樣的 action,這樣的情況表示 policy 實質上的行為就是一個函數,那麼我們稱這個 policy 為 policy function。所以說讀者千萬別把 policy 和 policy function 當成是一樣的東西。
另外讀者可能會看到 deterministic policy 和 stochastic policy,我們把 policy、policy function、deterministic policy 和 stochastic policy 當做是四個集合,那麼:
- policy function ⊂ policy
- deterministic policy ≡ policy function
- deterministic policy ∩ stochastic policy ≡ ∅
- deterministic policy ∪ stochastic policy ≡ policy
5.2 Value iteration
Value iteration 其實就是把前面 V(s) 的 Bellman operator T 變成實際程式而已。由於我們不確定到底要做幾次 T 才能得到 V*(s),所以我們可以用一個進步幅度來決定何時停止,也就是說當 V’(s) 和 V(s) 的差距小到一定程度,我們就可以停止迭代,並利用前面提過的方法得到近似或確切的 optimal policy。
直接看 pseudocode 吧,該講的之前都講過了,不熟悉的讀者可以閱讀前面的 Existence of optimal policies 和 Optimal policy construction 兩個小節。
以下動圖是 value iteration 解之前 MDP 的過程。

5.3 Policy iteration
Policy iteration 的思想很簡單,由兩個部分組成,前面有說過一個 policy 對應一個 value function,而一個 value function 對應至少一個 policy 對吧?Policy iteration 就是利用上面的精神來一次次迭代「近似」 𝜋* 。
為什麼要說近似呢?因為要得到 𝜋* 的迭代次數可能很大,所以我們需要取捨,用個近似的 policy 來表示 𝜋*,當然如果時間夠的話是可以得到 𝜋* 的。
Policy iteration 的過程看起來像是:
- 決定初始的 𝜋₀
- 根據 𝜋₀ 計算出 V₀
- 根據 V₀ 產生新的 𝜋₁
- 根據 𝜋₁ 計算出 V₁
- 根據 V₁ 產生新的 𝜋₂
- …
在上面的過程中有五個問題需要解答,分別是:
- 什麼叫決定初始的 policy?
- 什麼叫根據 policy 計算 value function?
- 什麼叫根據 value function 產生 policy?
- 什麼時候停止?
- 為什麼會收斂?
什麼叫決定初始的 policy?
最簡單的方法是讓所有的 state 都只會選擇某個固定的 action,當然隨機設定 PMF 的機率也可以,不過要注意隨機給的機率要滿足 PMF 的定義,也就是說全部的 action 的機率加起來要是 1。
什麼叫根據 policy 計算 value function?
這個步驟的具體名稱叫 value-determination 或 policy evaluation。給定 𝜋 後,根據之前的討論,我們可以透過解線性方程組來得到精確的 value function,這是一種方法,不過令 n 表 state 的數量,考慮到解線性方程組的時間複雜度為 O(n³),顯然當 n 大一點計算開銷就會很大,那麼有沒有替代的方法可以得到一組近似的 value function 呢?答案是有的,還記得 V(s) 的遞迴公式嗎?按原本的定義,我們應該要迭代無窮次遞迴公式才能得到確切的 V(s),不過這不可能也沒必要做到,我們可以計算幾次取個 V(s) 的近似值就好,至於計算的次數可以用 V(s) 的更新幅度來決定,例如前一次計算得到 V(s) = 1,下一次計算得到 V(s) = 1.1,如果覺得 0.1 的更新幅度足夠小的話,那就可以停止了。
什麼叫根據 value function 產生 policy?
這個步驟的具體名稱叫 policy improvement。當得到 V(s) 後,可以利用下面的式子來得到 state s 下的 optimal action a*,再令 𝜋[a*|s] = 1,這個方法有點像前面建構 optimal policy 的思路。
有發現 T 的痕跡嗎?這個式子實際上是把 T 的 max 改成 argmax 而已。利用這個方法得到的 policy 叫 greedy policy,因為我們只是單純看哪個 action 給得到的 expected return 最大,學過演算法的讀者可以跟演算法提到的 greedy 連結起來。
什麼時候停止?
簡單的做法是當 policy 不再變動時就停止整個流程,當然也能設定最大的迭代次數,當 policy 更新到一定次數後停止。
為什麼會收斂?
經過上面的操作,顯然 𝜋₁ 一定不比 𝜋₀ 差,𝜋₂ 一定不比 𝜋₁ 差,𝜋₃ 一定不比 𝜋₂ 差 ……,以此類推,換言之就是 V₁ 一定不比 V₀ 差,V₂ 一定不比 V₁ 差,V₃ 一定不比 V₂ 差 ……,這跟上一章節的 contraction mapping 的概念是一樣的,相信讀者不會對 policy iteration 會收斂得到 𝜋* 和 V*(s) 的結論感到懷疑,當然,有興趣的讀者可以試著證明 policy evaluation 加上 policy improvement 合在一起形成的操作是個 contraction mapping,我這邊就不多加著墨了。
解答完這五個問題,我們來看看 policy iteration 的 pseudocode 長怎樣,這應該是絕大部分讀者感興趣的部分。因為假設 policy 符合 function 的定義,所以 V(s) 公式最外面的 expectation 被我拔掉了。
接下來是使用 policy iteration 解之前的 MDP 的全過程,請注意少部分步驟的順序跟上面的 pseudocode 不一致,原因是不改一下順序的話圖真的很難做,做完圖之後我完全理解為什麼很多文章都直接把 Sutton(RL 奠基人之一)書上的圖偷過來用。
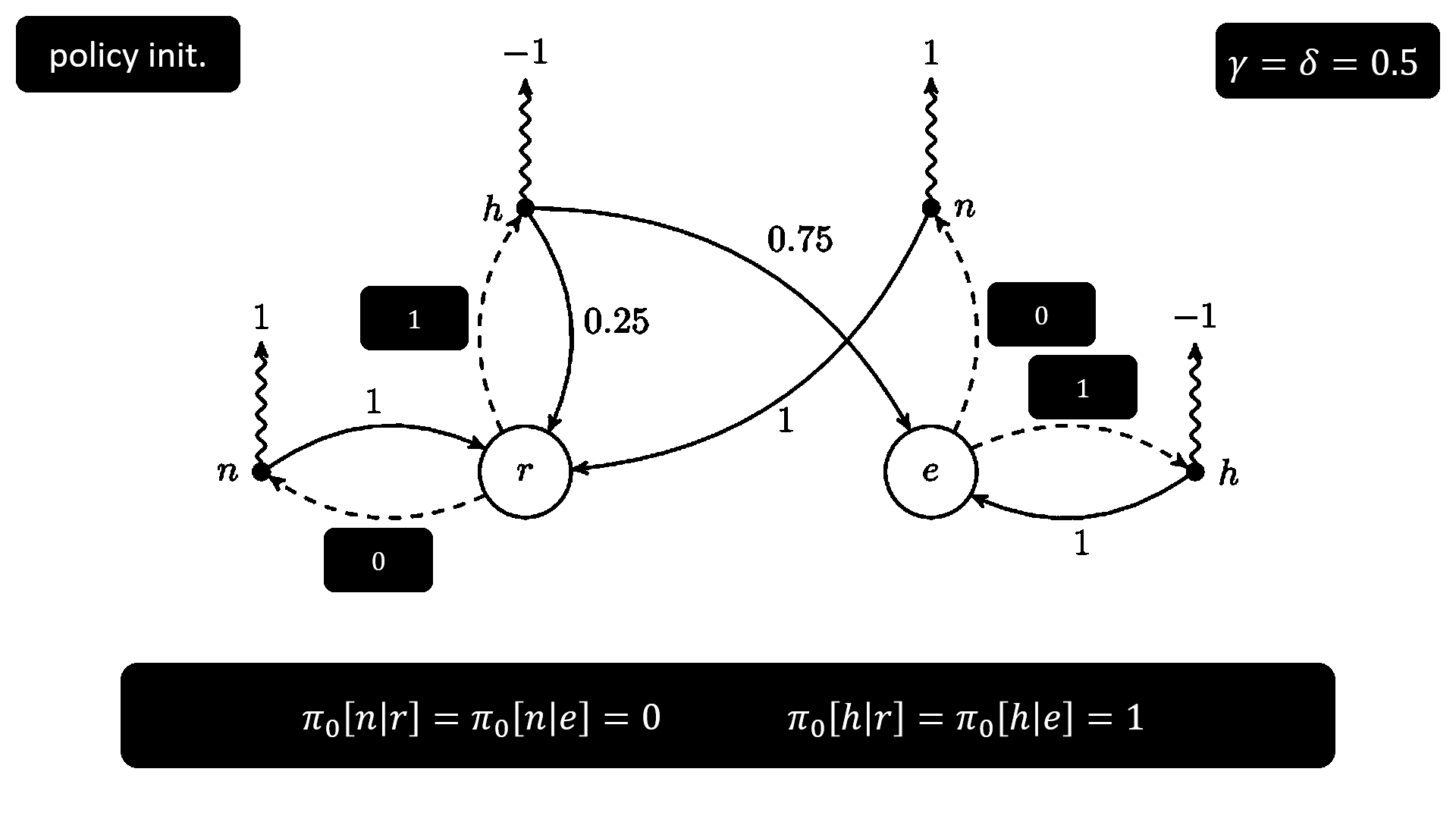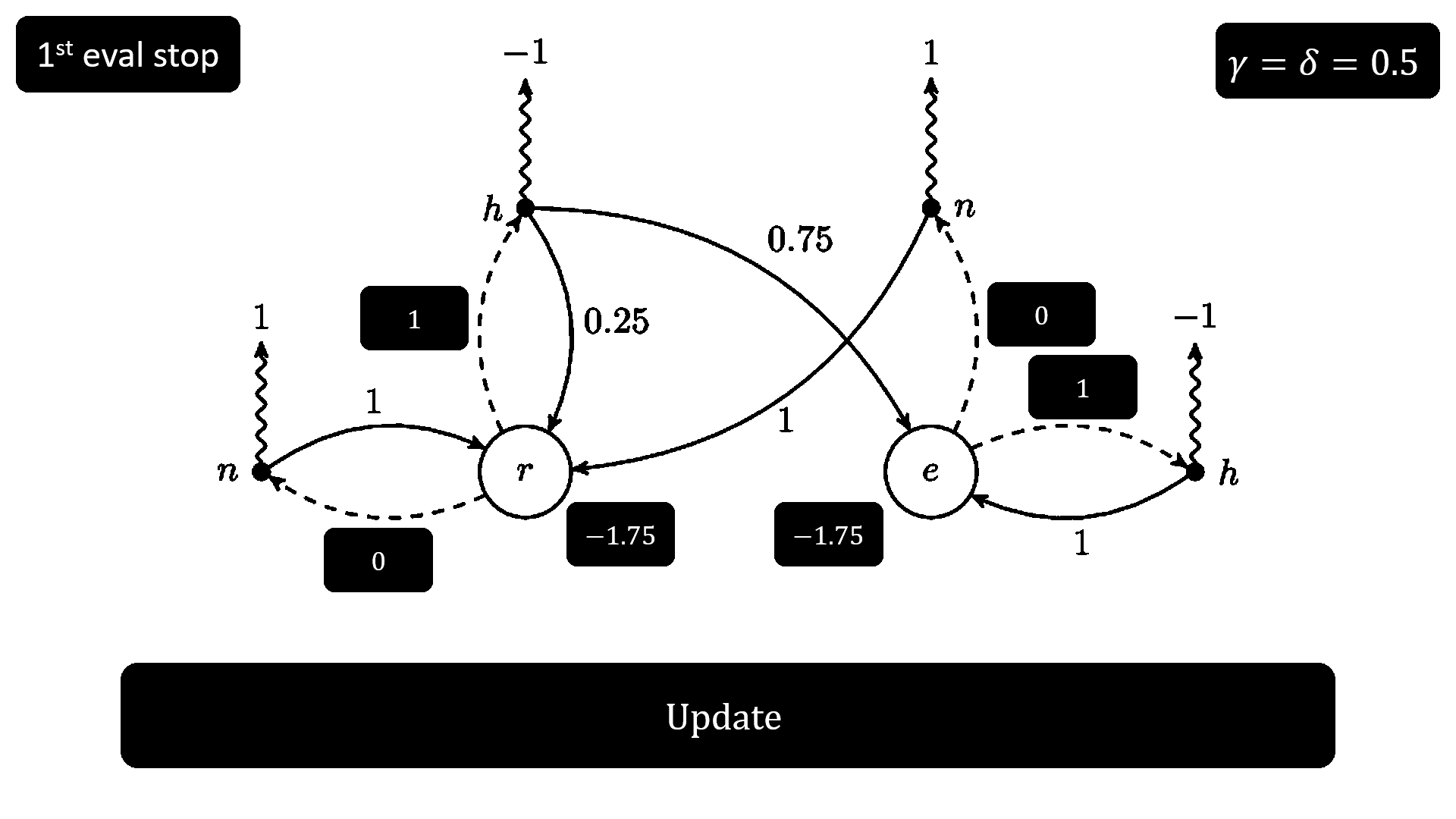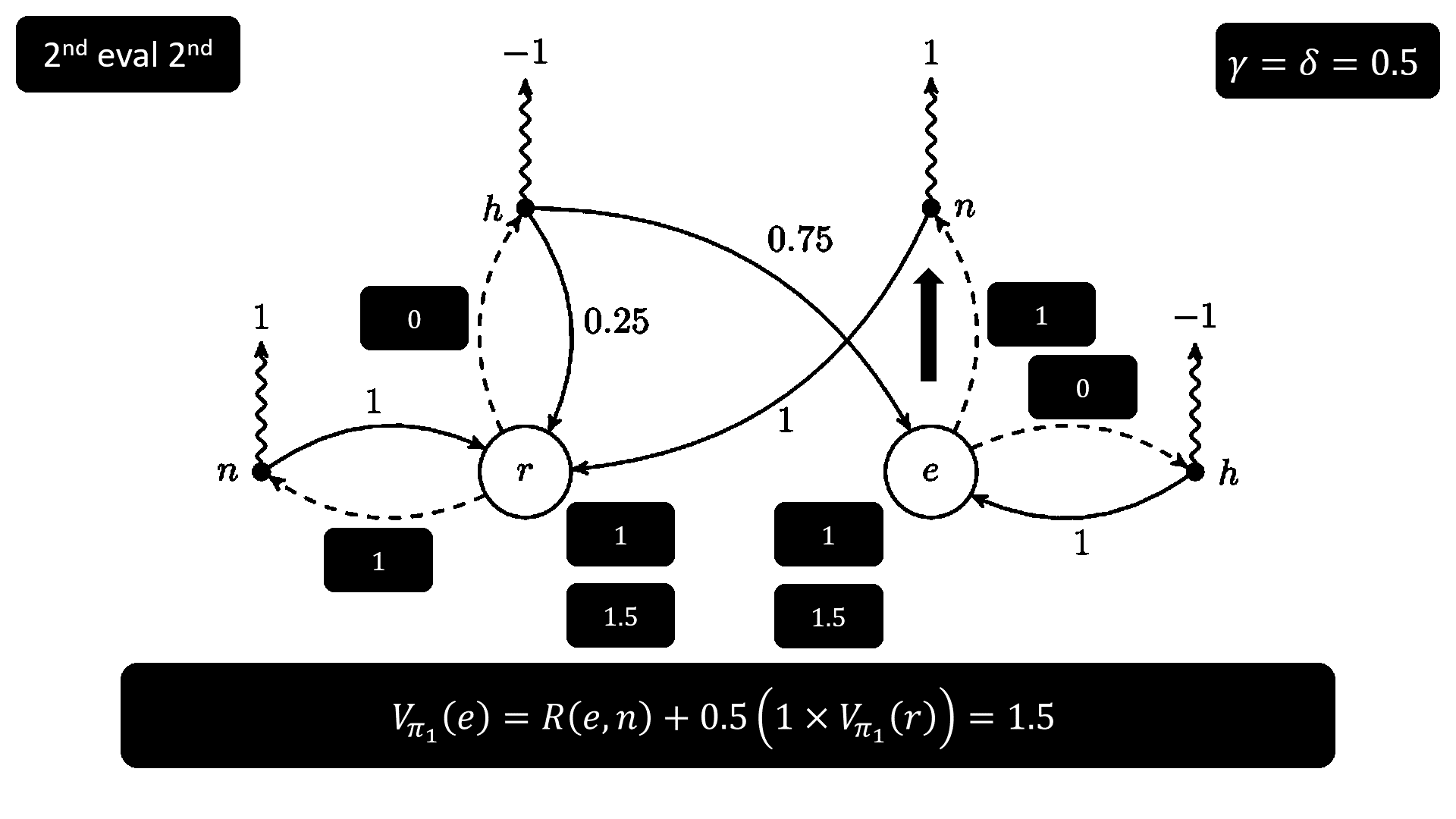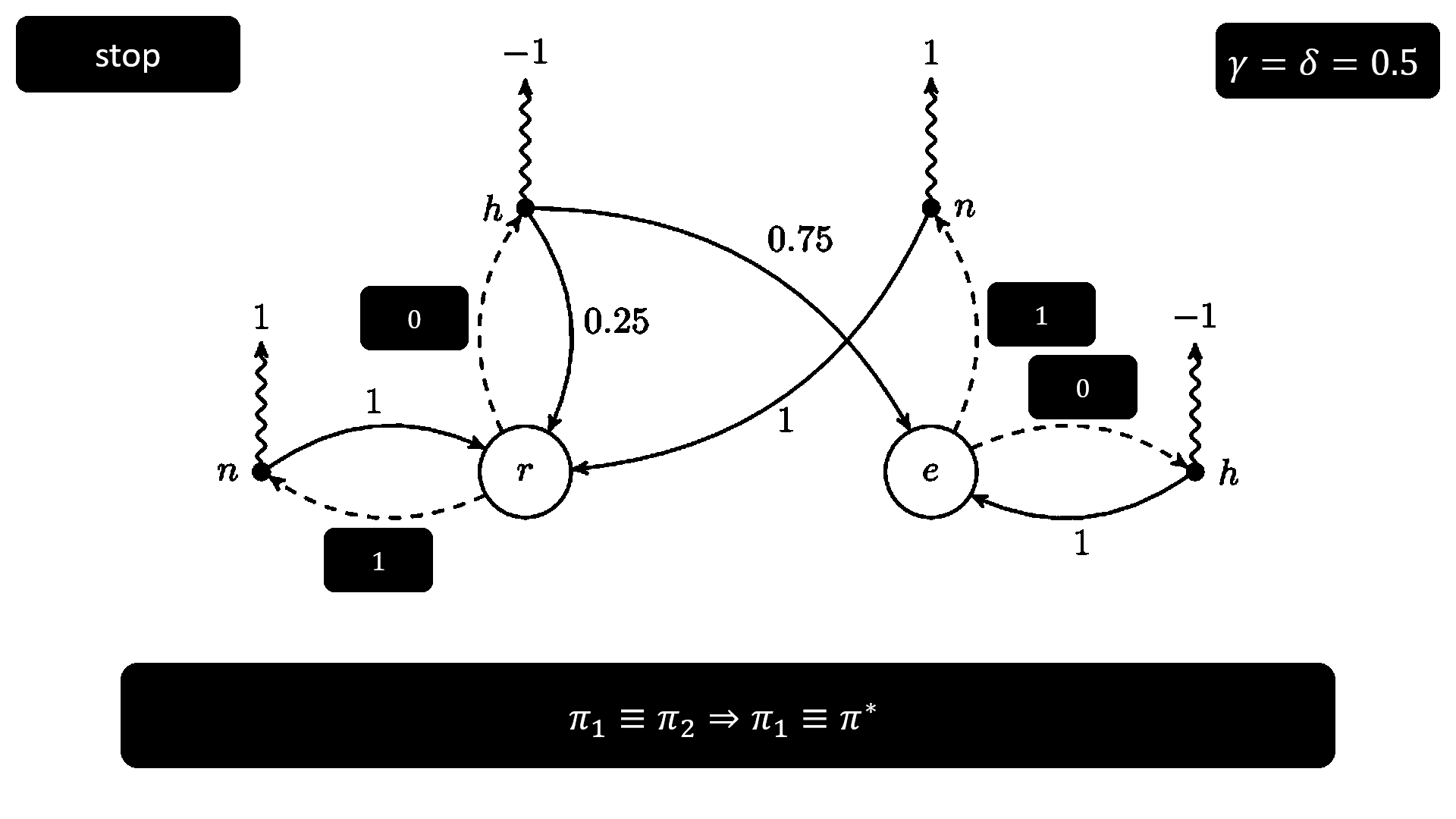
Policy iteration 是在 1960 年由 R. A. Howard 在他的著作 Dynamic Programming and Markov Processes 中提出,而 value iteration 源自 1957 年由 Bellman 撰寫的 Dynamic Programming 一書,也就是說前者比後者晚了三年,不過在 Sutton 的書中是先介紹 policy iteration 再講 value iteration,原因可能是 value iteration 的速度比 policy iteration 快。
我根據上面 MDP 的架構,使用不同 ℙ、R、γ 和 δ 對 value iteration 和 policy iteration 進行了測試,不知道是不是 MDP 架構太簡單還是我程式沒寫好,value iteration 在所有情況下都優於 policy iteration,不過這個結果也有跡可循,因為 value iteration 直接迭代 value function,而 policy iteration 是透過迭代 policy function 而來。
5.4 Monte Carlo method
在這裡提到的 Monte Carlo method 的概念很簡單,當 ℙ 或 R 或兩者都不知道時,我們可以進行大量的隨機動作來統計出近似的 ℙ 或 R,有了近似的 ℙ 或 R,我們就能套用 policy iteration 或 value iteration 來近似得到 𝜋*。
如果遇到不會終止的 MDP,例如上面的例子,那麼我們可以設定一個停止的長度即可。
套用上面的 MDP,假設只知道 A = {n, h} 和起始 state 是 r,那麼我們進行 5 個動作得到一個 sequence 為 {s₀, a₀, r₀, s₁, a₁, r₁, …, s₄, a₄, r₄, s₅} = {r, n, 1, r, h, −1, r, h, −1, e, h, −1, e, n, 1, r},當然在實際使用時,我們會採樣大量 sequence 才進行統計,不過在這個例子裡,用上面的 sequence 就夠了。
state, action | next state | count
--------------+------------+------
r + n | r | 1
r + h | r | 1
r + h | e | 1
e + h | e | 1
e + n | r | 1state, action | count | reward
--------------+-------+-------
r + n | 1 | 1
r + h | 2 | -1, -1
e + h | 1 | -1
e + n | 1 | 1
因為 Medium 沒有表格,所以我用文字呈現上面 sequence 的統計結果。
根據表格,我們可以得到:
- S = {r, e}
- ℙ[r|r, n] = 1/1 = 1
- ℙ[r|r, h] = 1/2 = 0.5(有兩個 r + h,所以要除 2)
- ℙ[e|r, h] = 1/2 = 0.5
- ℙ[e|e, h] = 1/1 = 1
- ℙ[r|e, n] = 1/1 = 1
- R(r, n) = 1/1 = 1
- R(r, h) = ((−1) + (−1))/2 = −1
- R(e, h) = −1/1 = −1
- R(e, n) = 1/1 = 1
也就是說由 sequence 估計的 MDP 會長這樣:
接下來套用 policy iteration 或 value iteration 就能得到近似的 𝜋*。(因為這個例子非常簡單,所以得到的會是 optimal policy)
5.5 Exercises
- 實作 value iteration 的 pseudocode,並驗證動圖的過程是否正確。
- 見 policy iteration 的 pseudocode,請問能將
evaluate()中的V ← V'併到上面的迴圈裡,變成V(s) ← V'(s)嗎?為什麼? - 實作 policy iteration 的 pseudocode,並驗證動圖的過程是否正確。
- 分析 value iteration 和 policy iteration 的異同。
參考資料
- DeepMind. Introduction to Reinforcement Learning with David Silver. (May. 1, 2020). Accessed: Jan. 6, 2022. [Online Video]. Available: https://www.youtube.com/playlist?list=PLqYmG7hTraZBiG_XpjnPrSNw-1XQaM_gB
- A. Modirshanechi. “Why does the optimal policy exist?” towardsdatascience.com https://towardsdatascience.com/an-overview-of-classic-reinforcement-learning-algorithms-part-1-f79c8b87e5af (accessed Jan. 16, 2022).
- Pr∞f Wiki contributors. “Banach Fixed-Point Theorem.” proofwiki.org https://proofwiki.org/wiki/Banach_Fixed-Point_Theorem (accessed Jan 16, 2022).
- R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction. Cambridge, MA, USA: A Bradford Book, 2018.
- S. Causevic. “A Structural Overview of Reinforcement Learning Algorithms.” towardsdatascience.com https://towardsdatascience.com/an-overview-of-classic-reinforcement-learning-algorithms-part-1-f79c8b87e5af (accessed Jan. 5, 2022).
- M. Sugiyama, ” Statistical Reinforcement Learning: Modern Machine Learning Approaches. Chapman & Hall/CRC, 2013.
鳴謝
上述參考資料的作者
沒有他們分享的知識,這篇文章不可能出現。
TeX to Unicode
Tex to Unicode 是個 Chrome 的擴充功能,幫我節省自行尋找 Unicode 符號的時間。
TeX Math Here
Tex Math Here 是個 Chrome 的擴充功能,讓我能夠在不切換頁面的情況下,利用 LaTeX 語法產生相應的公式圖片,這在不支援 LaTeX 的 Medium 上是個福音。
pdfTeX & ImageMagick
pdfTex 是個將 TeX 原始碼轉換成 pdf 的程式,而 ImageMagick 是個提供命令列(command line)指令的影像處理程式,能夠把 pdf 轉換成 png。這一套軟體組合使我能夠透過 PGF/TikZ 繪製出複雜的狀態機,並得到可以上傳到 Medium 的圖片。
